ChatOps - o que é?
ChatOps é um termo muito creditado ao pessoal do Github. Se formos resumir, podemos dizer que é “conversation-driven development”. Usando um bot com plugins e scripts, os times podem automatizar tarefas e colaborar, jogando fora os procedimentos repetitivos e economizando tempo.
Para aplicar isso, os times usam bots para automatizar os procedimentos manuais e repetitivos. Alguns dos mais conhecidos são o Hubot e o Lita.

Deployments práticos
Podemos usar bots para automatizar muitas coisas, como realizar backups, notificar colaboradores sobre algum evento (alguma modificação em issues/tasks, por exemplo), preparação de novos ambientes, code deployments, etc. Hoje focarei mais no último: code deployments.
Sabe aquele procedimento chato que você teve que fazer com Shell Script? Copiava uma coisa pra uma máquina, rodava um script alí, mudava umas configurações e rodava a aplicação? É nele mesmo que vamos focar aqui. Vamos acabar com isso. Vamos mandar os bots fazerem tudo pra nós. Quando terminarem que nos avise.
Gostou da ideia?
Code deployments - Frequência e duração
A frequência do deploy do(s) produto(s) que você trabalha diariamente, provavelmente, tem relação com o tempo gasto para cada deployment que é feito nos ambientes de qualidade/staging e produção.
Esse assunto é velho, mas será que seu time está tirando o maior proveito possível deste processo? Não temos como saber, mas se os seus deploys não estão muito frequentes, talvez seja um sinal que é possível melhorar.
Contextualização
Esse negócio de ChatOps surgiu na minha vida profissional em um time que o adotou quando estava começando a trabalhar com alguns elementos que até relativamente pouco tempo atrás eram novidade: feature branches, microservices, etc. Meu desafio aqui, é relatar a experiência e os benefícios identificados em uma equipe em que tais práticas foram adotadas.
Claro que tudo é questão de perspectiva. Alguns times adotaram, outros não quiseram ou não tiveram necessidade. O fato é que hoje feature branches e microservices são assuntos massificados e muitas vezes precisamos tornar certos procedimentos mais eficientes, mas a história aqui é outra. Vamos em frente.
Até aqui… Lhe contextualizei o suficiente? Então voltemos a focar apenas no nosso processo de code deployment.
A vida do time antes do ChatOps
O processo de deploy durava até 30 minutos. O time utilizava apenas o Bamboo, da Atlassian, para integração contínua.
O elemento mais adequado para ser classificado como “legado” do nosso sistema é um servidor web, escrito em Java, que publica uma API REST para ser consumida pelo front-end e pelas aplicações móveis (iOS e Android). Este servidor Java, era o qual mais realizávamos deployments diariamente. Tanto pelo time de qualidade, quanto pelo time de operações, em produção. O processo de deploy era muito lento, e isso afetava principalmente o time de qualidade (QA).
O time de QA realizava procedimentos manuais como baixar o artefato (.war), fazer acesso remoto (SSH), etc. mas tudo começava pelo build, que era composto por:
- Rodar testes unitários;
- Gerar o artefato no servidor de CI (Bamboo);
- Rodar análise de qualidade do Sonarqube;
- Baixar o artefato gerado (.war);
- Enviar para o servidor e rodar um script para realizar a atualização.
Agora, imagine esses passos para cada feature branch a ser testado pela qualidade? Pois é! Muito tempo perdido! Além disso, o time de qualidade possuía alguns ambientes para testar, e eles precisavam saber de forma rápida qual versão/feature branch/revision estava rodando em cada um destes ambientes. Como resolver?
Com ChatOps!
Bots são divertidos
Nesse ponto, decidimos testar a ideia e encontramos o Hubot e outras ferramentas divertidas. Decidimos também descomplicar tudo que fosse possível, mantendo apenas o que fosse necessário para não retroceder na qualidade do software.
O Hubot nos permite usar CoffeeScript para criar scripts e construir comandos que fazem o trabalho daqueles passos manuais, assim podemos descarta-los.
Todo processo que antes era feito de forma manual ou que é dispendioso, podemos deixar por conta do Hubot.
Onde existem vários passos, podemos transformar em apenas um comando, como hubot do stuff e ele fará por você, como pode ver em uma das imagens mostradas anteriormente.
É nesse ponto que começa a diversão!
Nosso objetivo era realizar automaticamente todos aqueles procedimentos que precisavam ser feitos de forma semi-manual, focando no code deployment. O que quero dizer com focar no code deployment? O Bamboo realiza varias tasks para garantir a qualidade do software. Algumas dessas tasks são meio lentas, e se precisássemos esperar por elas diversas vezes por dia, resultava em muito tempo perdido.
Com isso, pelo menos por enquanto (quem sabe?), precisamos manter o Bamboo para continuar executando os procedimentos que asseguram o rastreio da qualidade do software, mas podemos utilizar outras ferramentas em paralelo para realizar o deploy. O Bamboo continua gerando artefatos, rodando Sonarqube, etc e, em paralelo, fazemos nossos deploys. :)
Precisamos de um aplicativo de IM (Instant Messaging) qualquer para utilizar com o Hubot (IRC, Flowdock, Slack, HipChat, etc). Escolhemos o Slack.
Até aqui:
- Matemos o Bamboo para rodar todas as tarefas que asseguram a qualidade do software;
- Escolhemos o Hubot para ser nosso bot.
- Escolhemos o Slack como IM.
Com ChatOps, o deployment pode ser iniciado por qualquer um e, ainda, de forma assíncrona. Desta forma, precisamos de um lugar para centralizar o controle de todos os deployments.
Por isso, precisamos entender um pouco a API de Deployments do Github, pois tudo gira em torno dela. É lá que vamos centralizar o controle de nossos deployments.
Descobrindo a API de Deployments do Github
O Github lançou há um tempo a API de Deployments. Resumindo, ela serve meio como um CRUD de deployments.
Você pode criar um Deployment e relacionar ele a uma revision/tag/branch do seu projeto/repositório.
O Github vai guardar isso e você pode registrar webhooks para que outra ferramenta faça alguma coisa após a criação deste deployment, como por exemplo realizar o deployment propriamente dito.
Esse deployment registrado no Github pode ter seu status atualizado (pending/started/completed).
Abaixo tem um diagrama de sequencia retirado de uma página do Github que fala sobre essa API de Deployments. Dê uma olhada:
+---------+ +--------+ +-----------+ +-------------+
| Tooling | | GitHub | | 3rd Party | | Your Server |
+---------+ +--------+ +-----------+ +-------------+
| | | |
| Create Deployment | | |
|--------------------->| | |
| | | |
| Deployment Created | | |
|<---------------------| | |
| | | |
| | Deployment Event | |
| |---------------------->| |
| | | SSH+Deploys |
| | |-------------------->|
| | | |
| | Deployment Status | |
| |<----------------------| |
| | | |
| | | Deploy Completed |
| | |<--------------------|
| | | |
| | Deployment Status | |
| |<----------------------| |
| | | |
Colando as partes
Tá. Agora vamos juntar as partes.
Tem um script do Hubot para registrar os deployments lá na API do Github. O hubot-deploy, do @atmos. Vamos usa-lo pra criar nosso deployments.
Porém, os deployments criados no Github precisam ser coordenados. É necessário também ter alguma ferramenta para receber os webhooks de deployment do Github. No diagrama acima, essa ferramenta está descrita como 3rd Party.
Tem um projeto, também de autoria do @atmos, para isso: o heaven.
O Heaven possui integração com diversas ferramentas de deployment. Sozinho ele basicamente consome a API do Github e identifica qual repositório precisa clonar e qual revision precisa fazer checkout. O resto do trabalho ele deixa com alguma ferramenta a sua escolha. Essa ferramenta pode ser uma das disponíveis ou facilmente você pode escrever uma simples classe Ruby e fazer do seu jeito.
Ele possui integração com fabric, capistrano, AWS OPSWorks e algumas outras já prontas.
Nós escolhemos utilizar o fabric, que é um framework simples feito em python para realizar deployments em múltiplas máquinas.
Lá é que rodamos o mvn clean package para gerar o .war (Java, não é?) e enviamos para o servidor, que está na nuvem (na AWS, no caso), realizamos as configurações e tudo que for necessário para deixar a aplicação atualizada e funcionando.
Hmm… E aí, tem vantagem?
No fim, ficou assim:
|
|
Um simples comando e todo o trabalho de deployment é feito pra nós:
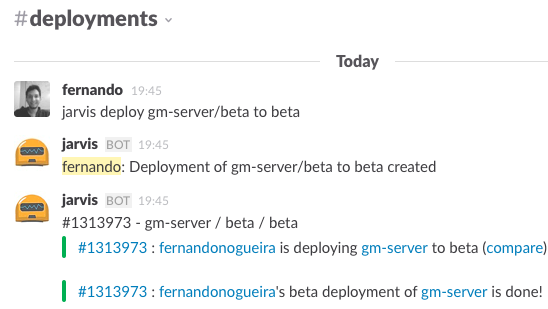
Como pode ver, o tempo para realizar o deployment e ter a aplicação funcionando, é de 3 minutos hoje em dia. Eu mencionei anteriormente que esse tempo era por volta de ~15 minutos.
Além disso, todos do time podem ver o que está acontecendo e quais ambientes estão sendo utilizados. Isso economiza tempo. Ninguém precisa parar ninguém para perguntar. (Lembra que antes o time precisava criar um controle para saber qual versão/branch estava em cada ambiente?!)
O hubot-deploy também disponibiliza outros comandos interessantes como o que lista os deployments realizados em um ambiente específico: hubot deploys PROJECT in ENV. Esse comando ajuda a saber quais feature branches estão aplicados em cada um dos seus ambientes ou qual versão está em produção, por exemplo.
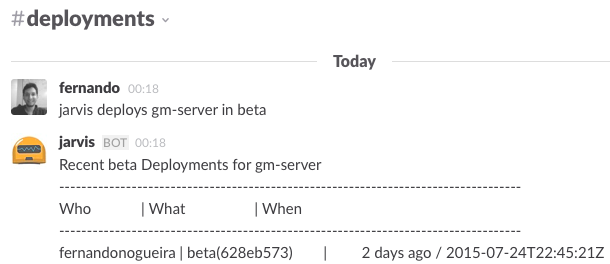
Isso tudo deixou o time mais rápido, os deployments mais rápidos e, consequentemente, melhorou todo o processo do time em geral, mitigando o tempo perdido com tudo o que foi mencionado neste post.
Posteriormente, caso exista interesse, posso criar um tutorial envolvendo hubot, hubot-deploy, heaven e fabric.
Mas e aí? Será que isso traria alguma vantagem para o seu time? Isso é só uma das poucas coisas que podemos fazer com o Hubot. ;)
Revisões:
14 Jun 2016 :)